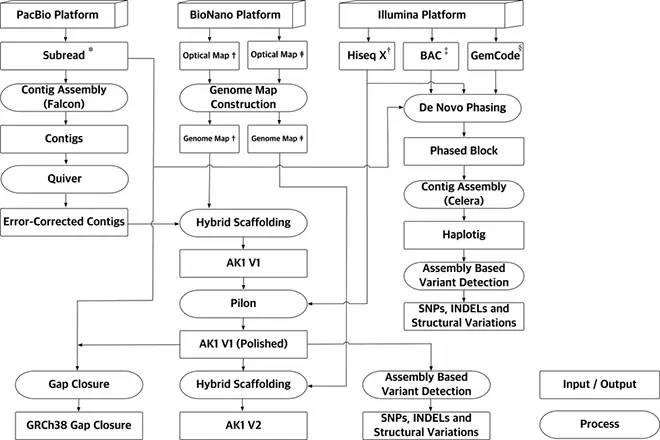
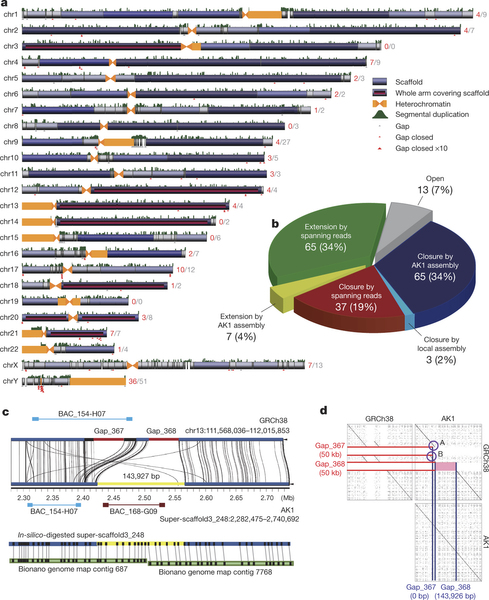
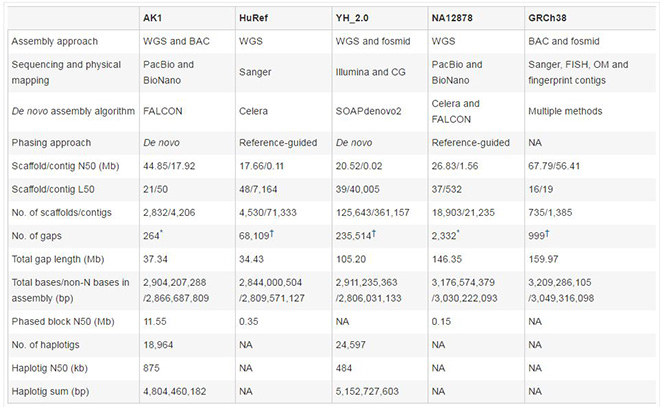
基因君官网
基因君官网
2016年10月25日 讯 /生物谷BIOON/ –我们人类总是会认为,相比地球上其它活的物种而言我们处于最顶端,生命从单细胞生物开始进化了超过30亿年,直到如今地球上具有多种形态尺寸以及不同能力的植物和动物,此外,随着生态复杂性的增加,在生命的历史长河中,我们看到了智力、复杂的社会能力以及科技创新的不断发展。
从自然角度来讲,生命历史的进展是从简单到复杂,而且这也正反映在了基因数量的增多上,我们以卓越的智慧和全球的统治力为我们的发展带路,人类是最复杂的生物,其有着一套非常精细化的基因群体。大约在半个世纪前,有研究推测人类机体中的基因有数百万个,如今这些基因的数量下降到了2万个,如今我们都知道,比如说香蕉都有3万个基因,其基因数量大约是人类基因的1.5倍。随着研究者们深入研究,他们设计出了既能够计算有机体基因数量,又能够发现不必要的基因的特殊方法。
对基因进行计数
我们可以认为机体中所有的基因都是我们烹饪的食谱,其以DNA碱基对的形式被书写(ATCG),这些基因能够提供提供指令来指导机体合成组成机体的蛋白质并且行使着不同的功能;一个标准的基因需要大约1000个碱基字母,结合不同的环境,基因往往会负责其所扮演的不同角色,因此到底有多少基因能够构成一个完整的有机体呢?
当我们谈论到基因数量时,我们常常会表示我们能对病毒进行实际计数,但目前研究者对真核生物进行计数面临的一个挑战就是我们机体的基因或许并不是像鸭子一样连续地排成了一队。我们机体烹饪书中遗传食谱的排列方式往往会被打断,并且会混入30万个其它的字母,大约50%实际上都被描述为失活死亡的病毒,因此在真核生物中很难对具有关键功能基因进行计数。
相比较而言,对病毒和细菌基因进行计数就简单地多,这是因为基因的原料—核苷酸对于小型生物而言非常珍贵,因此小型生物在进化过程中会通过较强的选择剔除掉那些不必要的序列,实际上对于病毒而言最大的挑战就是如何最初发现它们,令人惊讶的是,所有主要病毒的发现,包括HIV等,都并不是通过测序实现的,而是通过一些古老的方法,比如说将其放大到可见程度或者观察期形态学特征,分子生物学技术的发展教会了研究者如何探索病毒世界的多样性,但其仅仅能够帮助我们对已知存在的病毒的基因进行计数。

越少越繁荣
在人类整个基因组中,需要维持健康生命/生活的基因数量实际上要远远少于当前所估计的2万个基因,近日就有研究进行研究发现,维持人类生命的必要基因的数量或许非常少。研究人员对数千名个体进行研究,寻找其基因组中天然发生的“敲除”现象,即寻找那些“不在场”的特殊基因,我们所有的基因都有着连个拷贝,其中一个来自上一辈,通常情况下如果当基因另一个拷贝失活时,另一个活性拷贝就会进行功能性的弥补,研究者很难发现携带两个基因拷贝都失活的个体,因为失活的基因在天然状态下非常罕见。
研究敲除基因的功能在实验室对大鼠进行研究就可以,研究者们会利用现代的遗传工程技术来对目的基因进行失活操作,或者移除该基因来观察该基因失活后机体的表现;但对人类的研究需要生活在21世纪医疗技术时代的人群,而且还需要找到适合进行遗传学和统计学研究分析的谱系群体,冰岛人就是一类非常有用的研究对象。
研究者通过研究发现,有700多个基因被敲除后并不会带来明显的健康影响,比如,研究者指出,名为PRDM9的基因在小鼠的生育能力上扮演着重要作用,但如果在人类机体中被敲除后却不会引发任何疾病症状。基于对人类敲除研究进行推测性分析,研究这表示,实际上人类仅需要3000个基因就能够制造出一个健康完整的自己,这就类似于一种“巨大病毒”— 潘多拉病毒,2014年该病毒从3万年的西伯利亚冰川中复苏过来,其是目前研究者知道的最大的病毒,该病毒有2500个基因。
那么我们还需要什么基因呢?我们甚至并不知道四分之一的人类基因到底能干什么?到底其发挥着什么样的作用?

复杂源于简单
但是是否人类基因真正的数量时2万?3000个?或者是别的数量呢?问题的焦点就是当我们理解基因的复杂性时,大小或许真的并不重要了。数学家Alan Turing提出了一种多细胞发育的理论,他研究了简单的数学模型,名为反应-扩散过程,在这种过程中,少数的化学物质会发生扩散并且相互反应;随着简单规则指导机体反应的情况下,这些模型或许就能够产生一些非常复杂的拟序结构,因此植物和动物的生物学结构或许并不需要复杂的编程。
类似地,很显然人类大脑中有着100万亿个连接,这才是真正制造我们的本源所在,但我们或许并不可能对其进行单一性地遗传编程操作,近来一项在人工智能上的突破性研究就是基于大脑神经网络开展的,所谓人工智能就是拥有简单元件(和神经元类似)的大脑计算机模型,其能够通过与外界相互作用来建立一定的联系,而相关研究结果推测,在应用领域内,比如手写识别和医疗诊断中,Google公司就会邀请公众来同人工智能计算机来打游戏以及观察梦境。

微生物已经超越了基础的世界
因此,很显然,单细胞并不需要非常复杂的数量来产生非常复杂的效应,那么人类机体基因的数量或许就和单细胞的微生物,比如病毒和细菌一样,具有相同的尺寸。非常微小的微生物都有着极其丰富、复杂的生命,当然近几年不断兴起的社会微生物学就是研究微生物世界极其复杂“社会关系”的一门学科。
过去10年里研究者通过研究发现,微生物会将其90%的生命以生物被膜的形式存在,这或许是一种最有效有力的一种生物学组织,的确许多生物被膜都同细胞间有着复杂的通讯机制,就像大脑组织一样,这或许能够启发科学家们开发一种新型模型来研究诸如偏头痛和癫痫症等脑部障碍。
生物被膜被认为是“微生物的城市”,如今社会微生物以及相关的医学研究近些年取得了快速的发展,比如囊性纤维化的疗法开发商,居住在“城市”中的微生物也会互相协作、发生竞争、自杀等等一系列活动,因此其或许会成为21世纪科学家们在进化生物学中从事的重点领域研究之一。
人类的生物学机制或许远比我们想象地要更加杰出,当然对微生物世界的研究或许也会变得非常有趣,而关于基因的数量似乎同生命的奥秘并没有什么关系。(基因宝jiyinbao.com)
本文系生物谷原创编译整理,欢迎转发,转载需授权!点击 获取授权 。更多资讯请下载 生物谷app.
参考资料:
【1】Between a chicken and a grape: estimating the number of human genes
Genome Biology DOI: 10.1186/gb-2010-11-5-206
【2】The banana (Musa acuminata) genome and the evolution of monocotyledonous plants
Nature doi:10.1038/nature11241
【3】Protein length in eukaryotic and prokaryotic proteomes
Nucleic Acids Research doi: 10.1093/nar/gki615
【4】Repetitive DNA and next-generation sequencing: computational challenges and solutions
Nature Reviews Genetics doi:10.1038/nrg3117
【5】The evolutionary ecology of molecular replicators
Royal Society Open Science DOI: 10.1098/rsos.160235
【6】Next-generation sequencing in clinical virology: Discovery of new viruses
World J Virology doi: 10.5501/WJV.v4.i3.265
【7】Marine viruses |[mdash]| major players in the global ecosystem
Nature Reviews Microbiology doi:10.1038/nrmicro1750
【8】Health and population effects of rare gene knockouts in adult humans with related parents
Science DOI: 10.1126/science.aac8624
【9】What makes species unique? The contribution of proteins with obscure features
Genome Biology DOI: 10.1186/gb-2006-7-7-r57
【10】The Social Lives of Microbes
Annual Review of Ecology, Evolution, and Systematics
DOI: 10.1146/annurev.ecolsys.38.091206.095740



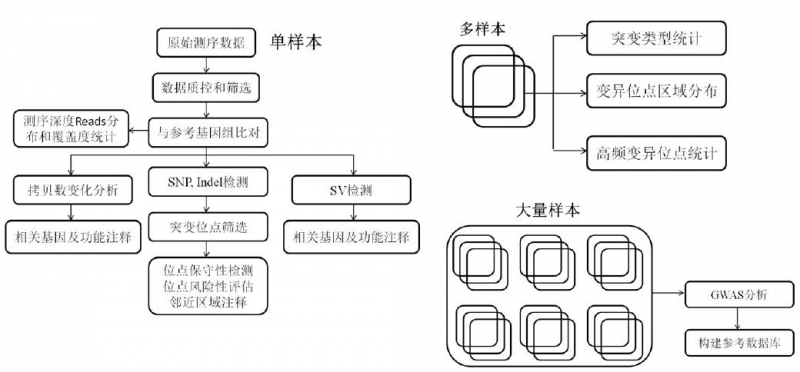
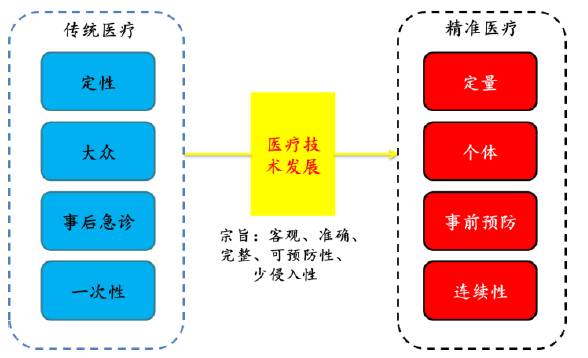
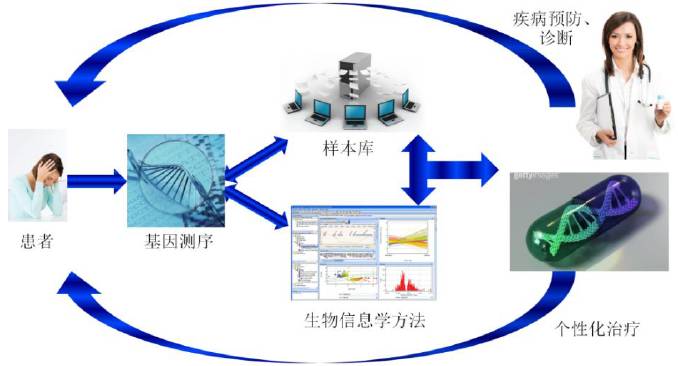
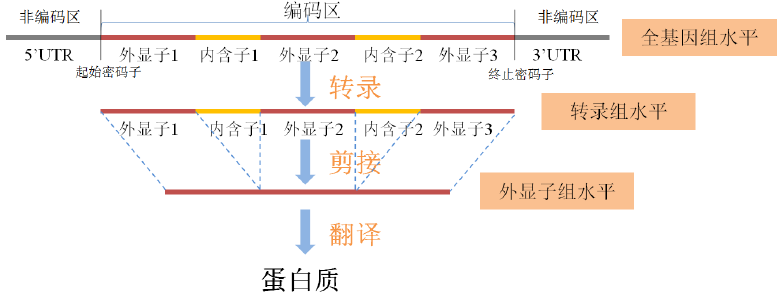







 在正常人的基因里潜伏着约54个看上去好像应该会令其携带者生病或死亡的突变。不过,它们并没有。Sonia Vallabh希望,D178N是这样一个突变。
在正常人的基因里潜伏着约54个看上去好像应该会令其携带者生病或死亡的突变。不过,它们并没有。Sonia Vallabh希望,D178N是这样一个突变。